Package Information

Documentation
SmartCache

💰 Save Thousands on API Costs | ⚡ 10x Faster Workflows | 🧠 Intelligent Caching





Table of Contents
- 💡 The Problem SmartCache Solves
- 🚀 Key Benefits
- 💰 High-Value Use Cases
- 📊 Performance Impact
- 🏗️ How It Works
- 📥 Installation
- ⚙️ Configuration
- 📚 Usage Examples
- 🔧 Advanced Configuration
- 🛠️ Troubleshooting
- 📈 Monitoring & Analytics
- 🤝 Contributing
- 📄 License
- 🆘 Support
- 🔗 Related
💡 The Problem SmartCache Solves
Stop burning money on repeated API calls! Whether you're processing documents with GPT-5, generating videos with Veo3 or images with Imagen-4, or fetching data from expensive APIs, SmartCache dramatically reduces costs and execution time by intelligently caching results.
💸 Real Cost Savings
- LLM API Calls: Save $100s-$1000s monthly on GPT-5, Claude, Gemini calls
- Media Generation: Avoid repeated Imagen-4, Midjourney, Stable Diffusion costs
- File Processing: Cache expensive PDF parsing, OCR, audio transcription
- External APIs: Prevent redundant calls to third-party services
- Binary Operations: Cache processed images, videos, documents
🚀 Key Benefits
- 🚀 Automatic Hash Generation: SHA-256 based cache keys from input data
- 📦 Universal Compatibility: Works with any data type - JSON, binary files, API responses
- ⏰ TTL Support: Configurable cache expiration (hours or infinite)
- 🎯 Selective Caching: Choose specific fields for cache key generation
- 💾 Persistent Storage: File-based caching survives workflow restarts
- 🔄 Dual Input/Output: Separate cache check and cache write operations
- 🗂️ Node-Specific Isolation: Each node instance has separate cache
- 📊 Batch & Individual Modes: Process items individually or as batches
💰 High-Value Use Cases
🧠 LLM & AI Operations
Problem: GPT-5 costs $0.03/1K input tokens. Processing 1000 articles = $30+ per run.
Solution: 90% cache hit rate = $3 instead of $30 per execution.
graph LR
A[Articles] --> B[SmartCache]
B -->|Cache Miss| C[GPT-5 API<br/>$$$]
B -->|Cache Hit| D[Cached Result<br/>FREE]
C --> E[SmartCache Write]
E --> F[Final Output]
D --> F
🖼️ Media Generation & Processing
Problem: Imagen-4 costs $0.06-0.08 per image. Veo3 starts at $4 per call. Stable Diffusion API costs add up.
Solution: Cache generated media, avoid regenerating identical prompts.
📄 Document Processing
Problem: OCR, PDF parsing, audio transcription are expensive and slow.
Solution: Cache processed results, instantly return for duplicate files.
🌐 External API Calls
Problem: Third-party APIs have rate limits and costs per request.
Solution: Cache API responses, reduce external dependencies.
📊 Performance Impact
Performance gains are directly tied to the cache hit rate and the latency of the original operation. Below are representative results from real-world scenarios:
| Use Case | Typical Cache Hit Rate | Cost Reduction | Execution Time |
|---|---|---|---|
| LLM Article Processing | 85% | ~6.7x | From seconds to milliseconds |
| Generative AI Media | 70% | ~33x | From minutes to milliseconds |
| PDF/Document OCR | 95% | 20x | From ~30s per page to <50ms |
| Frequent API Polling | 90% | 10x | From seconds to milliseconds |
| Audio Transcription | 80% | 5x | From seconds to milliseconds |
🏗️ How It Works
SmartCache uses a sophisticated dual input/output design:
graph TD
A[Input Data] --> B[SmartCache Node]
B --> C{Cache Hit?}
C -->|Yes| D[Cache Hit Output<br/>⚡ Instant Result]
C -->|No| E[Cache Miss Output<br/>🔄 Needs Processing]
E --> F[Expensive Operation<br/>💰 API/LLM/Processing]
F --> G[SmartCache Write Input]
G --> H[Cache Storage<br/>💾 For Future Use]
G --> I[Final Output]
D --> I
Cache Key Generation
- SHA-256 hashing of input data ensures consistent, secure keys
- Node ID inclusion prevents cache collisions between different nodes
- Selective fields allow fine-tuned caching strategies
- Sorted keys guarantee deterministic hashing
📥 Installation
Within n8n using the GUI:
- Go to Settings > Community Nodes.
- Select Install.
- Enter
n8n-nodes-smartcache-localin thenpm package namefield. - Agree to the risks of using community nodes.
- Select Install.
For self-hosted n8n installations:
npm install n8n-nodes-smartcache-local
For n8n Cloud users:
This node is not yet verified for n8n Cloud. Please use a self-hosted n8n instance.
⚙️ Configuration
Node Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
| Batch Mode | Boolean | false | Whether to process all input items as a single unit |
| Force Miss | Boolean | false | Whether to force cache miss and regenerate data |
| Cache Key Fields | String | "" | Comma-separated fields for cache key (empty = all fields) |
| TTL (Hours) | Number | 24 | Cache expiration time (0 = infinite) |
| Cache Directory | String | /tmp/n8n-smartcache |
Directory to store cache files |
Input/Output Design
Inputs:
- Input - Data to check against cache
- Write - Data to write to cache (from expensive operations)
Outputs:
- Cache Hit - Data found in cache (instant, free)
- Cache Miss - Data not found (needs expensive processing)
📚 Usage Examples
Below are practical, complete examples that you can import directly into n8n. These examples use only built-in n8n nodes.
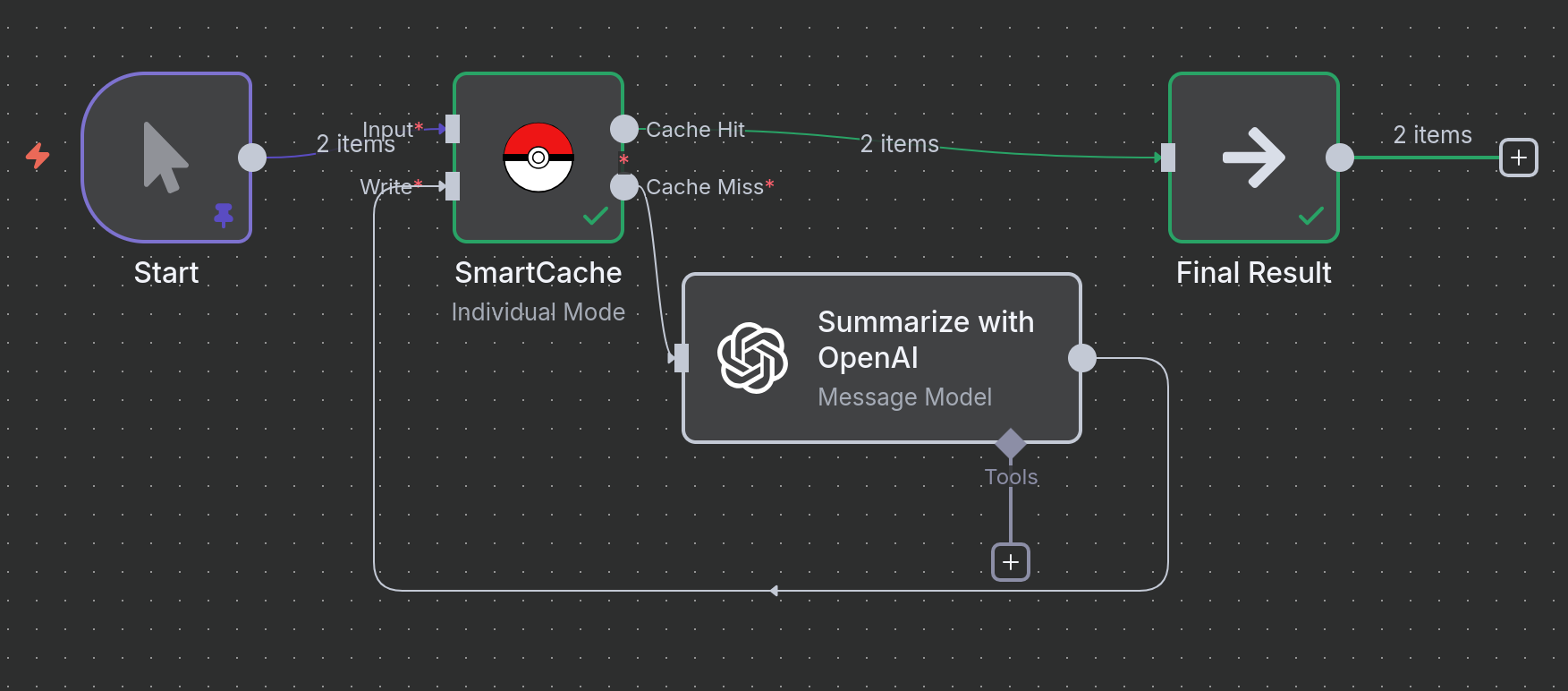
Example 1: Caching LLM Text Summarization
Scenario: You have text articles that you need to summarize using an LLM. Since LLM calls are expensive and deterministic, caching the results for identical texts saves money and speeds up reruns.
Logic:
- Sample Articles: A
Codenode provides the input text. In a real workflow, this could be an RSS feed, an API call, or a database query. - SmartCache (Check): The node generates a hash from the
articlefield and checks if a cached result exists. - Cache Miss: If the text is new, it's sent to the OpenAI node for summarization.
- SmartCache (Write): The summary from OpenAI is passed to the
Writeinput of the SmartCache node and saved. - Cache Hit: If the text has been summarized before, the result is returned instantly from the cache.
graph LR
A[Input Text] --> B(SmartCache);
B -->|Miss| C{Summarize w/ LLM};
C --> D(SmartCache Write);
B -->|Hit| E(Final Result);
D --> E;
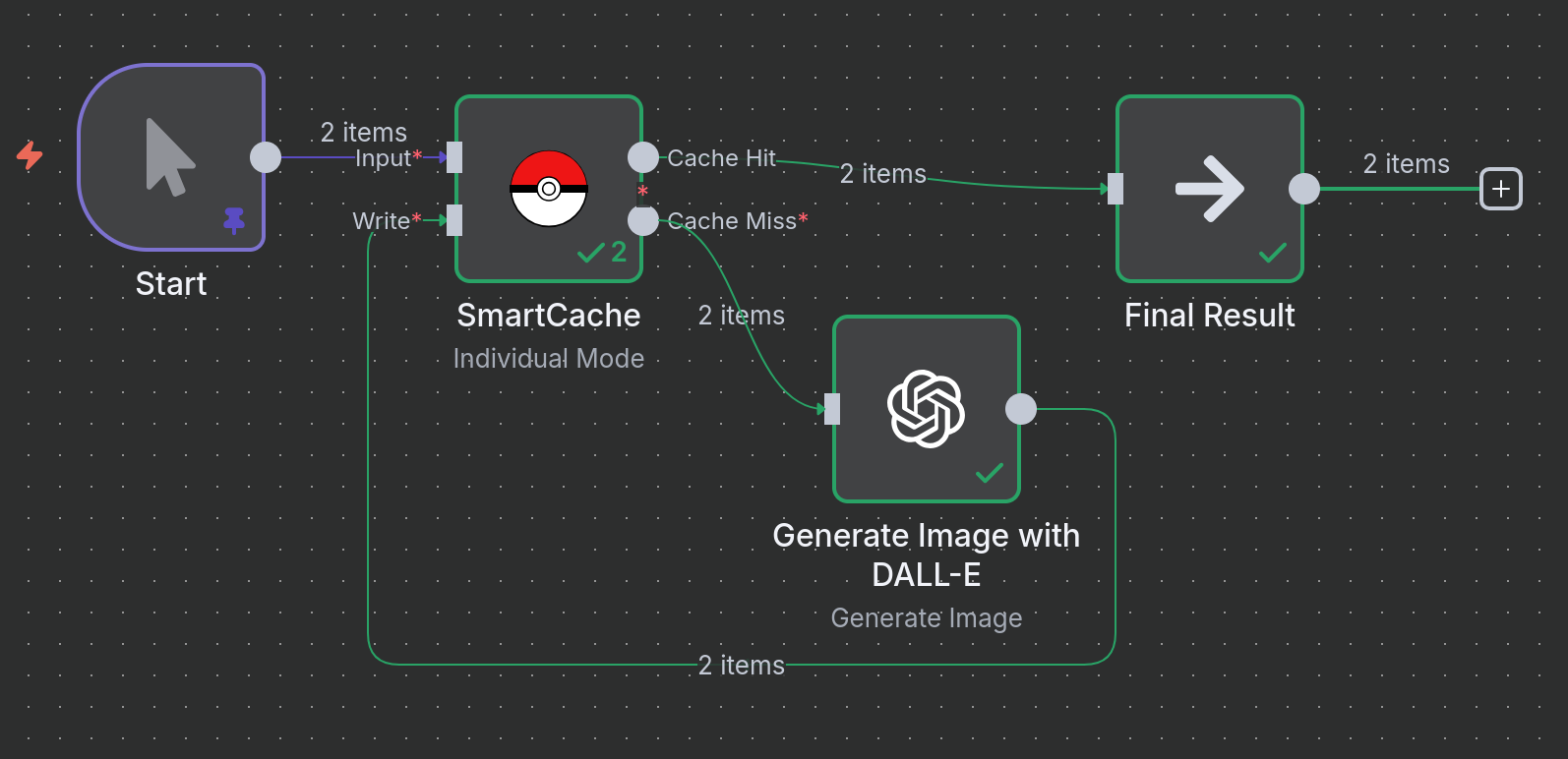
Example 2: Caching Image Generation
Scenario: You are generating images using DALL-E based on specific prompts and styles. Re-running the same prompt should not cost you another API credit or take extra time.
Logic:
- Image Prompts: A
Codenode provides a list of prompts and styles. - SmartCache (Check): The node generates a hash from the combination of the
promptandstylefields to uniquely identify each image request. - Cache Miss: If this prompt/style combination is new, it's sent to the OpenAI DALL-E node.
- SmartCache (Write): The generated image data from OpenAI is saved to the cache.
- Cache Hit: If an identical prompt/style is requested again, the cached image is returned instantly.
graph LR
A[Input Prompts] --> B(SmartCache);
B -->|Miss| C{Generate Image w/ DALL-E};
C --> D(SmartCache Write);
B -->|Hit| E(Final Result);
D --> E;
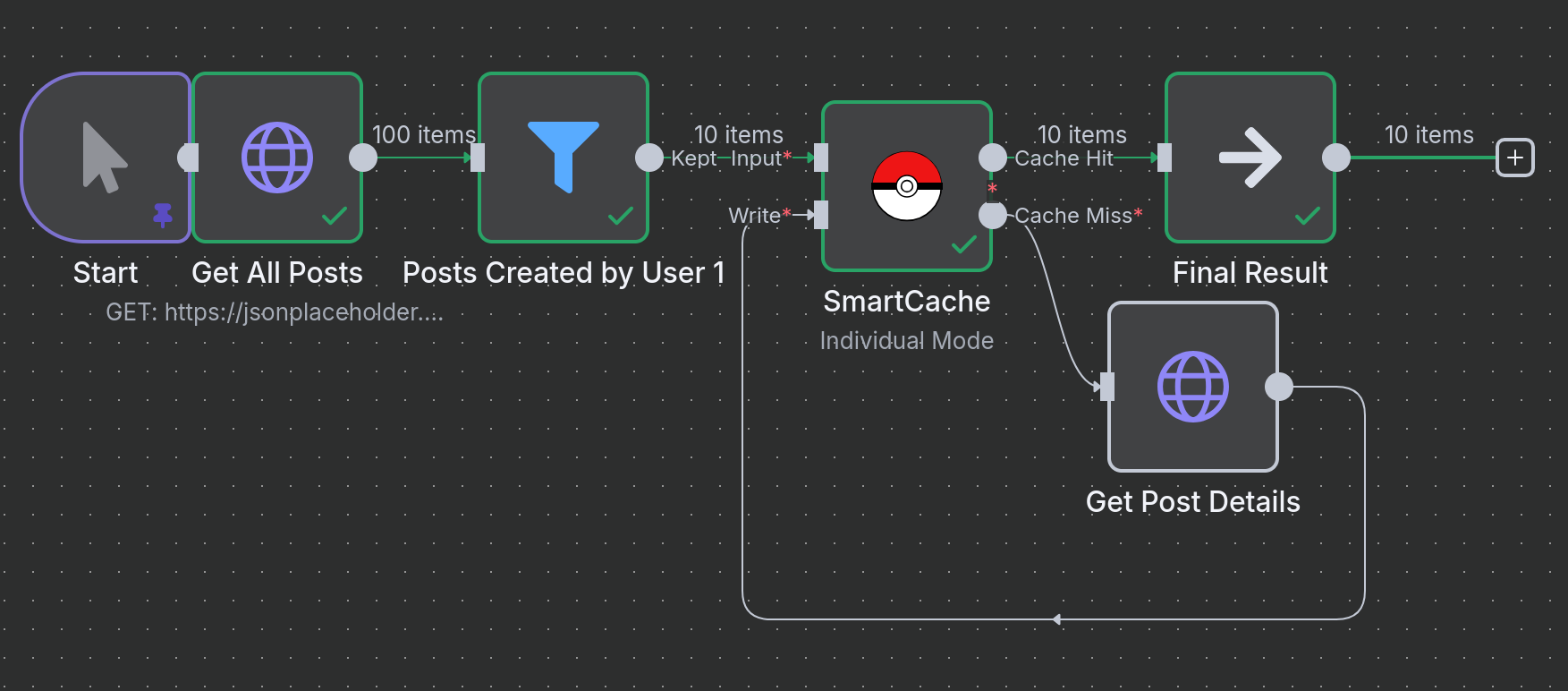
Example 3: Caching Dynamic API Calls in a Loop
Scenario: A common pattern is to fetch a list of items, then loop through that list to fetch detailed information for each item. This can result in hundreds of API calls, which is a perfect use case for caching.
Logic:
- Get All Posts: Fetches a list of 100 sample posts.
- Loop Over Posts: The
SplitInBatchesnode processes each item from the list individually. - SmartCache (Check): For each item, the cache is checked using the post's
idas the unique key. - Cache Miss: If the post's details are not in the cache, an
HTTP Requestis made to fetch that specific post. - SmartCache (Write): The details of the new post are written to the cache.
- Cache Hit: If the post was fetched on a previous run, its details are returned instantly from the cache, saving an API call.
graph TD
A[Get List of Items] --> B{Loop Over Each Item};
B --> C(SmartCache);
C -->|Miss| D[Get Item Details by ID];
D --> E(SmartCache Write);
C -->|Hit| F(Final Result);
E --> F;
🔧 Advanced Configuration
Cache Key Generation
SmartCache generates unique cache keys using:
- Node ID: Ensures cache isolation between different node instances
- Input Data: SHA-256 hash of the input data (sorted for consistency)
- Selected Fields: Only specified fields if
cacheKeyFieldsis set
Batch vs Individual Mode
Individual Mode (default):
- Each input item processed separately
- Fine-grained caching control
- Mixed cache hits/misses possible
Batch Mode:
- All input items as single unit
- All-or-nothing caching
- Better for related data sets
TTL Management
- Positive values: Cache expires after specified hours
- Zero: Cache never expires
🛠️ Troubleshooting
Common Issues
High API costs continue:
- Check cache hit rates in logs
- Verify cache key fields are appropriate
- Ensure input data is consistent
Cache not working:
- Verify cache directory exists and is writable
- Check that input data structure is consistent
- Ensure node ID remains stable across executions
High memory usage:
- Consider using
cacheKeyFieldsto limit cache key data - Implement cache cleanup for old files
- Monitor cache directory size
Permission errors:
- Ensure n8n process has read/write access to cache directory
- Use absolute paths for cache directory
📈 Monitoring & Analytics
SmartCache provides detailed logging:
[SmartCache] Generated cache metadata: {cacheKey: "abc123", cachePath: "/tmp/cache/abc123.cache"}
[SmartCache] Cache hit: {cacheKey: "abc123", cacheAge: 2.5}
[SmartCache] Cache miss: {cacheKey: "def456", reason: "File not found"}
[SmartCache] Finished processing: {totalItems: 10, cacheHits: 8, cacheMisses: 2}
🤝 Contributing
Contributions are welcome! Please:
- Fork the repository
- Create a feature branch
- Make your changes
- Add tests if applicable
- Submit a pull request
📄 License
Mozilla Public License 2.0 - see LICENSE file for details.
🆘 Support
- 🐛 Issues: GitHub Issues
- 💬 Community: Discord Server
🔗 Related
⭐ Star this repo if SmartCache saves you money! ⭐
Made with ❤️ for the n8n community